

Have you scrolled through your favorite online store, and come across an item that immediately catches your fancy? But checking the price with that much anticipation you find it at a high price, Aargh!! Now, you start weighing how tiring it will be to constantly check every day for a price drop.
What if we could write a Python code that could monitor the price and send us an email when the price drops with a little note attached, “Hey you! Go purchase that birken bag now, it is a $100.” fascinating right? Okay now, enough with the fantasies, fasten your seatbelt because we are about to make that a reality.
{kind=link}
Visiting the Amazon Webpage
Amazon website would be used in this article; you can use any site afterward, but stick with it for this article, okay? On the Amazon homepage, navigate to the search bar and type in the name of an item of your choice— I am going for my favorite dream pair heels.
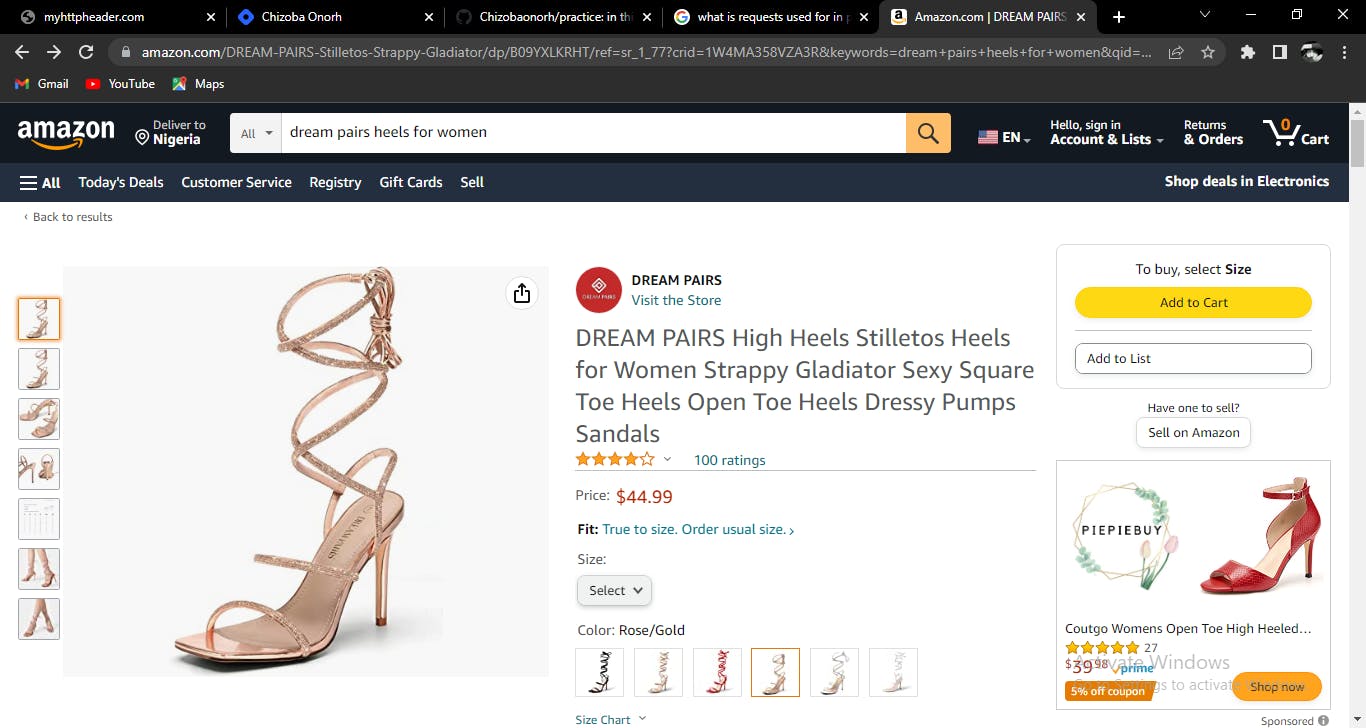
We would be scraping this particular page to get the “Amazon-government” name of the item and price.
Importing Requests Module and Making Requests
Requests is a package used for making HTTP requests that allow us to send and fetch data from websites. We will use this package to get access to the Amazon website data in our Python code.
Run the pip install requests command in your terminal if you don’t have the package. Next, import the requests package into your code. This package has an inbuilt method that fetches data from the net once a URL is passed into it: the .get() method.
import requests
Copy the link to the current page that displays the item and save it in a variable “URL” (make sure to type in the particular item you are looking for; this will display a full working link). We could have gotten away with just a URL using any website, but due to Amazon’s strict policy, we are required to authenticate our browser. Visit myhttpheader.com and fetch your User-Agent and Accept-Language data. This information will be passed in the form of a dictionary to a header variable.
URL = "https://www.amazon.com/DREAM-PAIRS-Stilletos-Strappy-Gladiator/dp/B09YXLKRHT/ref=sr_1_77?crid=1W4MA358VZA3R&keywords=dream+pairs+heels+for+women&qid=1678839652&sprefix=dream+pairs%2Caps%2C360&sr=8-77"
header= {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36",
"Accept-Language": "fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7"
}
We call the requests.get() method and pass in the URL and header in this format, this fetches an object which we would save in a response variable. To understand objects in Python refer to this article
response = requests.get(url=URL, headers=header)
If you print(response) it gives an output of <Response 200>, signifying we have been allowed access. Drilling further, we are going to fetch the text of this website and display it in our IDE using the .text method; we save this in a feedback variable. Printing this would display the whole HTML code of the website.
feedback = response.text
print(feedback)
Using Beautiful Soup to Parse and Scrape Our Webpage
The beautiful soup module helps to scrape and fetch data from websites into our python code for our personal use with the help of an HTML parser.
Install the bs4 module and also the lxml module; these would be handy tools we would use to scrape and parse our website. After installation, import the BeautifulSoup class from the bs4 package and also lxml.
from bs4 import BeautifulSoup
import lxml
The class BeautifulSoup will take in the input of a particular website and a parser which in this case is the lxml. This would create an object that can be used to extract various texts and tags by calling different methods on it. For more understanding of how to use this module click here
soup = BeautifulSoup(feedback, “lxml”)
Now, let’s head back to the amazon website to fetch the price tag and name of our selected item. On the webpage, locate the price tag and right-click on it, select inspect on the box that pops up. This automatically exposes the HTML code of the website and also highlights the particular tag where the price is embedded.
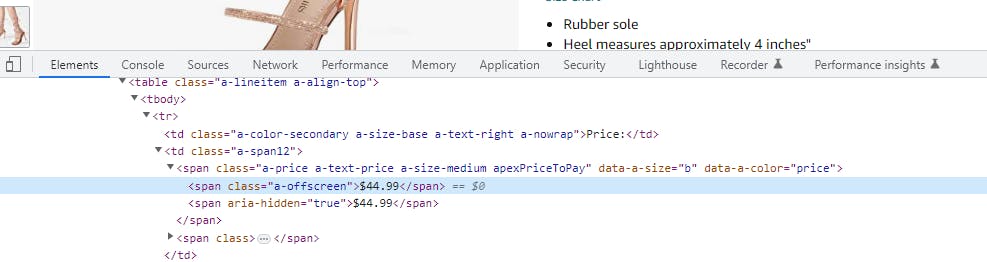
Take note of the name of the tag and its unique attribute. In my case, it has the span tag and has a class of a-offscreen. Note: class in bs4 is represented as class_. To scrape and fetch this particular tag, we call the .find() method and pass our span and class in this format.
price_tag = soup.find(name="span", class_="a-offscreen")
we save our result in a price_tag variable; Run print(price_tag) to visualize the output. Note: the print function is helpful to understand what we are doing at each point.
However, we are not looking to fetch an HTML tag but the price, hence, we dig even deeper to get the price. We call another method .getText() that gets the text in between an opening and closing tag.
price = price_tag.getText()
this immediately outputs our price when printed out.
Go ahead and repeat this to get the name of the item we are looking for; the same method, click on the item name and select inspect then look for the tag. In my case, the tag is in span with an id of productTitle.
name_tag = soup.find(name="span", id="productTitle").getText()
#I just modified this code and put the two separate codes on the same line
Comparing Item Price against our Set Price
Now let’s not forget the purpose of this project, we are building a program that immediately notifies us when the price drops to our specified number and send us an email. However, remember Python only allows comparison between integers and float numbers, and we got back our price as a string, hence, we need to tweak it into a floating point number.
We call the split() function on our current price, specifying a separator as the “$” sign. This creates a list with space and number. You can check out the split() for more clarity.
price_without_sign = price.split(“$”)
#This gives an output of a list with two string items, [“”, “44.99”]
#Using list index
amount = float(price_without_sign[1])
#In one line,
amount = float(price.split(“$”)[1])
#Comparing the prices
if amount < 44.90:
Pause…*
What do we intend to do when the price/amount goes down? We want to send an email right? Hence, we make use of the smtplib module used to send emails using python.
Install this package if you don’t have it, and import it into your code. I want to believe we know how to send emails with the smtplib module, if not, refer to this article.
Depending on the email provider we are using we would need a password that allows us access to send emails to ourselves. I would be using Gmail in this tutorial, with an smtp of smtp.gmail.com. You can find out the smtp of your email provider here.
Setting up…
connection = smtplib.SMTP("smtp.gmail.com", port= 587)
We create our object from this; next, we get our password if you are using Gmail. Go to your Gmail Google account setting, go to security and two-factor authentication, scroll down to app password and input a preferred name like Vscode or anything, click on generate and it would generate a password for you to use. Copy and paste that password into a variable "password". For other email providers, however, change your privacy settings to allow less secure apps access—you will not be needing a password in this case.
my_email = "rewardonorh@gmail.com"
password = "password"
#place your password in that string
We want to be able to send an email if the price goes below this:
if amount < 44.90:
connection.starttls()
connection.login(user=my_email, password=password)
connection.sendmail(from_addr=my_email, to_addrs=my_email, msg=f"Subject: Amazon Price Alert!\n\n{name}now ${amount}\n \nBuy now!\n {URL}")
connection.close()
Customize your “msg” anyhow that suits you. If you find this particular part confusing refer to this article.
And there we have it, once you follow these steps and run your code it should work. You should also consider adjusting the comparing price so you can get an email and be sure your code works. Also, clear out all the print() functions you had earlier to end up with a final code like this:
import requests
from bs4 import BeautifulSoup
import lxml
import smtplib
header= {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36",
"Accept-Language": "fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7"
}
URL = "https://www.amazon.com/DREAM-PAIRS-Stilletos-Strappy-Gladiator/dp/B09YXLKRHT/ref=sr_1_77?crid=1W4MA358VZA3R&keywords=dream+pairs+heels+for+women&qid=1678839652&sprefix=dream+pairs%2Caps%2C360&sr=8-77"
response = requests.get(URL, headers=header).text
soup = BeautifulSoup(response, "lxml")
price_tag = soup.find(name="span", class_="a-offscreen")
price = price_tag.getText()
name_tag = soup.find(name="span", id="productTitle").getText()
amount = float(price.getText().split("$")[1])
my_email = "rewardonorh@gmail.com"
password = "password"
connection = smtplib.SMTP("smtp.gmail.com", port= 587)
if amount < 44.90:
connection.starttls()
connection.login(user=my_email, password=password)
connection.sendmail(from_addr=my_email, to_addrs=my_email, msg=f"Subject: Amazon Price Alert!\n\n{name_tag}now ${amount}\n \nBuy now!\n {URL}")
connection.close()